在今天的移动应用程序中,带有位置标记的地图组件很常见. 例如, Airbnb的应用程序突出地展示了这样的标记, 从web服务获取, 表示映射上可用的属性.
以确保获取的数据量不会随着标记数量的增加而变得无法管理, 服务器在将这些标记发送到客户机之前将它们分组在一起. A 地图集群 一个特殊标记的位置是否等于它所包含的标记的平均位置. 它被标记为它所代表的标记的数量.
仍然, 服务集群会造成性能瓶颈,因为web服务必须从数据库中检索给定地理区域内的每个单个标记. 幸运的是,这个问题可以通过缓存策略来解决. 以便更好地理解如何设计和维护缓存, 让我们看一个示例映射API端点 playsport拍摄应用.
在Playsports地图中,每个标记代表一个体育设施. 地图的 API 端点需要返回一个标记和标记簇的列表, 给定缩放级别和边界框.
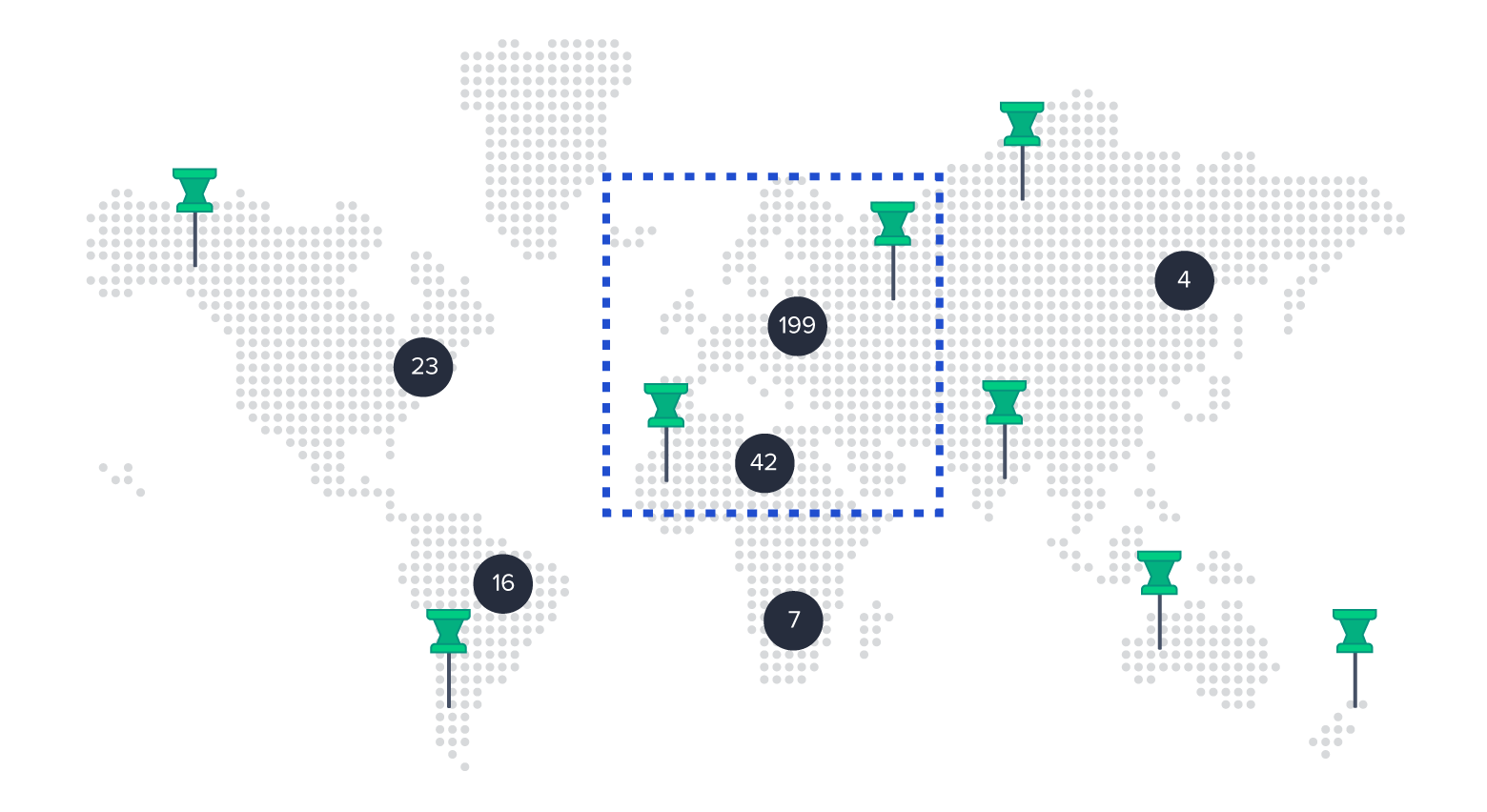
如果记号笔的数量足够少, 我们可以从数据库中加载边界框中的所有标记, 必要时进行集群, 并将生成的标记和集群返回给客户端.
一开始, 在Playsports中,任何可到达的边界框中标记的最大数量是~400, 导致端点速度为~0.5秒. 对于这个用例来说,实现简单的解决方案就足够了.
然而,随着标记数量的增加,该机制的低效率变得明显. 在我们增加了~10,000个新的体育设施标记后,端点速度减慢到~4.在某些缩放级别下3秒. 这个速率远低于通常认为的一秒的持续时间 最大可接受延迟 用于移动应用程序中的用户操作.
以便更好地理解幼稚解决方案的低效率, 让我们在标记查询的上下文中分析它:
随着标记数量的增加,步骤1和步骤2中的性能会下降:
假设窗口大小不变, 当边界框相对较大时, 缩放级别通常较低(例如.e.(缩小得很远). 在低变焦水平下,结果倾向于集群,以避免视觉拥挤. 因此, 优化的最大潜力在于解决方案的第一步, 那里装着成千上万个单独的标记. 结果中我们不需要这些标记中的大部分. 我们只需要将它们中的每一个算作一个簇.
朴素的解决方案需要更长的时间来完成最坏情况查询:标记密集区域中的最大边界框. 相比之下,优化后的解决方案只需要73 ms,代表了58倍的加速. 从高水平上看,它是这样的:
主要的复杂性在于缓存的架构.e.(第一步).
这一主要步骤由六个部分组成:
复述, 是通常用作缓存的快速内存数据库吗. 它的内置地理空间索引 使用Geohash算法 为实现经纬度点的高效存储和检索, 这正是我们的标记所需要的吗.
地图集群的程度(返回单个标记还是集群)由传递给端点的缩放级别决定.
谷歌Maps支持从0到最大20的缩放级别,具体取决于区域. (其他地图服务支持的范围类似. 例如,Mapbox使用从0到最大23的缩放级别.)因为这些缩放级别也是整数值, 我们可以简单地为每个缩放级别创建一个单独的缓存.
支持谷歌maps中的所有缩放级别-除了级别0, 哪个太大了,我们会创建20个不同的缓存. 每个缓存将存储整个地图的所有标记和集群, 作为它所代表的缩放级别的聚类.
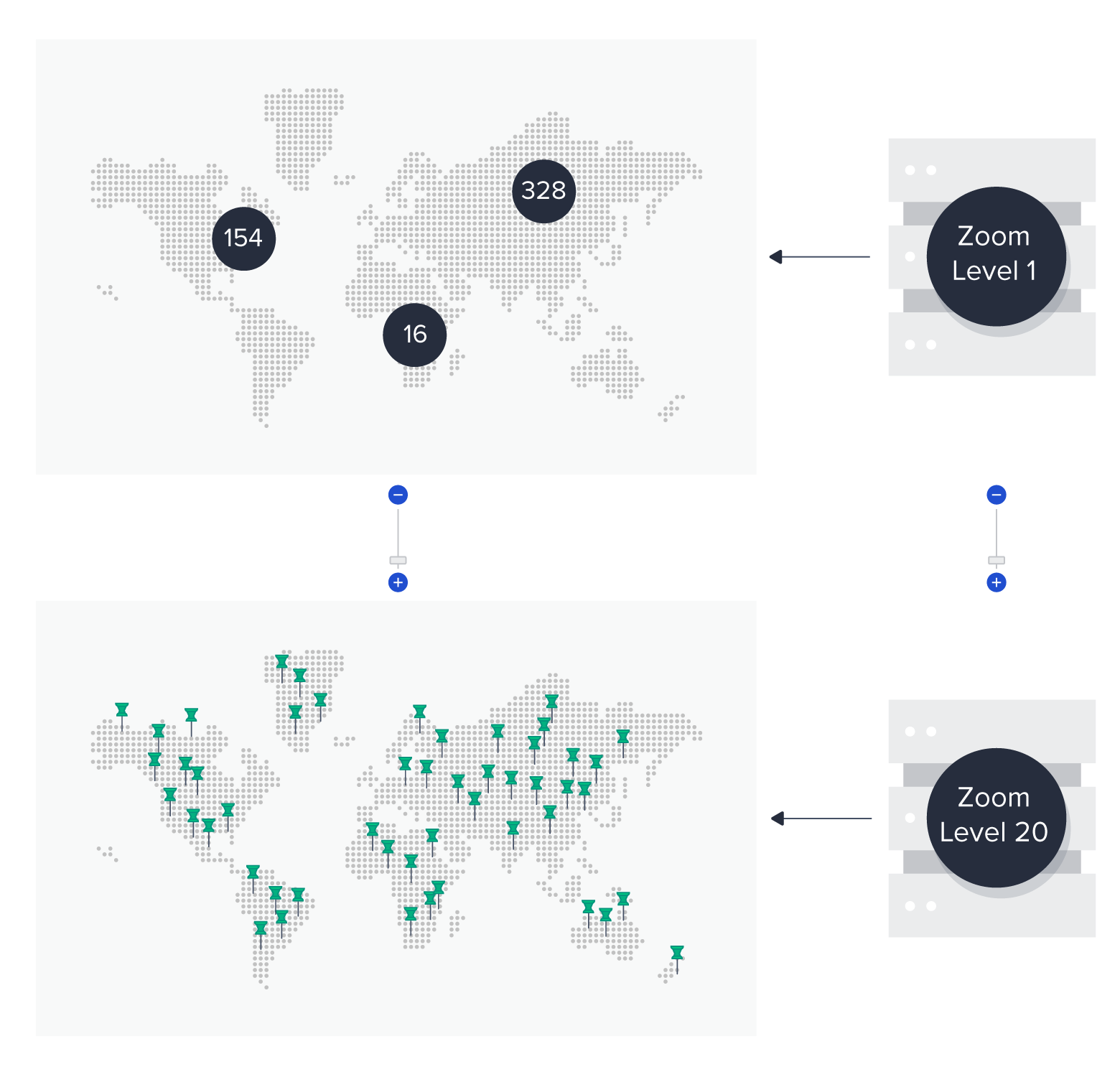
每个缓存将存储集群和单独的标记. 对于任何一种类型的条目,我们都需要填充几个字段:
| 字段名 | 请注意 |
|---|---|
| 类型 | 群集或标记 |
| 经纬度 | 为了方便起见,我们复制了复述,的内部地理空间存储. |
| ID (只适用于记号笔) | 在步骤2中,我们可以使用这个值来获取位置以外的详细信息,比如用户交互历史. |
|
包含标记的数量 (只适用于集群) | 在步骤2中,我们可以获取聚合数据(例如.g.(未查看标记的数量). |
然而, 复述,允许用户只存储位置, 加上一个字符串, 作为地理空间集合中的值. 为了绕过这个限制,我们将上述字段序列化为一个JSON字符串. 然后我们使用这个字符串作为复述,中的值. 复述,中键和值的最大大小都是512 MB, 对于这个用例,哪一个已经足够了.
为了填充缓存,我们从数据库中检索所有的标记. 对于每个缩放级别,我们执行地图聚类算法. 我们使用复述,。 GEOADD 将生成的标记和群集插入相应缩放级别的缓存中, 沿着经纬度传递, 加上前面描述的JSON字符串.
在此阶段在整个地图上运行地图聚类算法(而不是在用户的边界框上运行), 根据需要)理论上可能会在集群放置中产生一些边缘差异, 但整体用户体验将保持不变.
对于传入请求,我们将给定的边界框传递给复述, GEOSEARCH command, 哪个查询给定缩放级别的缓存以检索区域中的标记和群集候选.
20级缓存刷新的成本很高, 因此,最好在项目需求允许的情况下尽可能少地进行刷新. 例如, the addition or removal of a sports facility in Playsports only marks the cache as stale; an hourly cron job then refreshes the cache, 如果需要. 更多信息请参见缓存过期一节.
此时,大多数应用程序需要根据单个标记id获取详细信息. 我们可以将这些细节作为缓存中字符串化JSON值的一部分, 但在很多应用中, 标记细节是特定于用户的. 既然有单, 所有用户的共享缓存, 不可能将这些附加字段存储在那里.
我们优化的解决方案从缓存结果中获取单个标记的id,并从数据库中获取它们的详细信息. 现在我们只查找聚类后剩下的单个标记. 当地图缩小时(因为我们会有很多集群),或者当地图放大时(因为面积会很小),这些都不会太多。.
相反,朴素解向上看 所有 聚类前边界框中的标记(及其详细信息). 因此,这一步——可选,但对许多应用程序来说至关重要——现在运行得快多了.
构建了集群并增强了单个标记之后,我们现在可以将这些标记交付给客户机. 除了一些无关紧要的边缘情况, 得到的数据几乎与原始解决方案相同,但是我们能够更快地交付它.
现在让我们看看另外两个因素:
让我们假设一个应用的地图总共包含N个标记. 由于有多达20个缩放级别,我们最多需要存储20N个缓存项. 在实践中, 然而, 由于集群,缓存项的实际数量通常要低得多, 特别是在较低的变焦水平. 事实上,在所有Playsports的缓存中分配的缓存道具总数只有~2N个.
进一步, 如果我们假设缓存值(字符串化JSON)的长度为~250个字符(一个合理的假设), 至少对于Playsports),字符串大小为每个字符1字节, 那么JSON值所需的缓存存储量大约是2 * N * 250字节.
在这个图中,我们添加了复述,的内部数据结构,用于排序集 GEOADD. 复述,使用 85mb内存 对于100万个小键值对, 所以我们可以假设复述,内部占每个缓存项少于100字节. 这意味着我们可以使用1gb ram的复述,实例来支持多达1个复述,实例.400万笔. 即使在不太可能的情况下,标记均匀地分布在整个地图上, 导致缓存项数接近20N, N仍然可以达到~140,000. 由于一个复述,实例可以处理超过40亿个键(2)32确切地说,这不是一个限制因素.
根据用例的不同,仅仅定期刷新缓存可能是不够的. 在这种情况下,我们可以使用速率受限的任务队列. 这将减少缓存过期, 同时仍然限制缓存刷新的次数, 这就是系统的负荷.
在每次数据库更新之后,我们将对缓存刷新作业进行排队. 这个队列将把任务数量限制在每小时M个. 这种折衷方案允许比小时更快的更新,同时保持系统上相对较低的负载(取决于M)。.
playsports的优化方案——比原始方案快50多倍——效果很好. 它应该会继续正常工作,直到我们得到1.400万个标记或现有数据的100倍以上.
对于大多数基于地图的web服务请求, 需要某种形式的预计算来实现可伸缩性. 要使用的技术类型, 以及具体的设计, 是否取决于业务需求. 缓存过期需求, 标记扩增, 在设计解决方案时,标记的数量是需要考虑的重要特征.
图聚类, 或者标记聚类, 简化了地图,否则会有过多的标记.
标记集群是在服务器端完成的. 在视觉上, 每个标记密集的区域被替换为一个地图集群, 通常是一个圆圈,包含它所代表的单个标记的数目.
缓存的地图是在每个缩放级别上预先计算集群的地图,以便更快地访问.
世界级的文章,每周发一次.
世界级的文章,每周发一次.



 作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.
作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.